Transformer: All you need is Attention (설명/요약/정리)
트랜스포머는 퍼셉트론과 디셉티콘으로 나뉩니다.

문장과 같은 연결성이 중요한 sequence data에는 RNN 계열의 모델이 많이 사용됩니다. RNN은 직전의 출력 결과를 입력으로 재귀적으로 받아들여 활용합니다. 하지만, 이 장점은 곧 단점이 됩니다. 조금 멀리 떨어진 단어보다는 무조건 가까운 단어가 연관성이 높게 나타난다는 점입니다. 예를들어, "JYP는 SM엔터테인먼트, YG엔터테인먼트와 마찬가지로 박진영의 영어식 이름의 약자에서 따온 것이다"라는 문장을 생각해봅시다. JYP는 SM엔터테인먼트와 가깝고, 거리가 박진영와 멀다. 이러한 경우 RNN에서는 JYP와 박진영의 의미를 연결짓기 어렵습니다. 오히려 YG엔터테인먼트가 박진영에 대한 임팩트를 크게 가질 것입니다. 이러한 문제를 long-term dependency problem이라고 부릅니다. 이것을 해결하기 위해서 제안된 모델은 바로 LSTM(Long Short Term Memory)입니다. LSTM은 새로운 입력값 뿐만 아니라, 이전의 출력값을 잃어버릴지, 얼마나 받을지를 고려하는 gate들을 추가하여 상대적으로 멀리있는 워드에 영향을 전달할 수 있도록 합니다. 하지만, 이 역이 거리의 한계는 존재했고, 순차적으로 연산한다는 점에서 병렬처리에 어려움이 있어 연산량이 너무 많아 학습속도가 느렸습니다. (LSTM의 연산량을 줄이는 GRU도 제안되고, 계산 방법에 대한 것들도 제안되긴 하였습니다.) 이러한 문제점들을 해결하기 위하여 등장한 것이 바로 Attention입니다. 대표적인 자연어처리 문제인 기계 번역(machine translation)에 대한 예제로 Transformer 논문은 설명을 풀어나갑니다. 기계 번역은 encoder-decoder의 구조로 이루어져있으며, 이전 글 autoencoder를 참고하시면 좋을 것 같습니다.
[Deep Learning] - AutoEncoder (self-supervised learning)
AutoEncoder (self-supervised learning)
딥러닝에서 가장 대표적인 unsupervised learning 방식 중 하나인 autoencoder를 살펴보고자 한다. auto, 그리고 encoder는 각각 왜 붙여진 이름일까. encoder와 decoder를 먼저 보자. encode는 입력이 특정한 형..
lv99.tistory.com
transformer는 더 빠르고, 좋은 성능을 보였습니다. 논문에서는 영어를 독일어와 프랑스어로 번역하는 부분에서 성능을 증명합니다. RNN을 통해 계산한 값을 attnetion을 이용해 동적으로 encoder의 모든 상태값을 반영합니다. 그래서 기존의 encoder, decoder의 성능을 높였다고 합니다. 그리고 마침내 RNN 모델을 벗겨내어 Transformer로 속도와 성등을 모두 향상시킵니다.
attention은 이전 글을 참고하시면 좋을 것 같습니다.
[Deep Learning/Concepts] - Attention Mechanism (Jointly Learning to Align and Translate)
Attention Mechanism (Jointly Learning to Align and Translate)
Encoder-decoder 모델에서 중요한 특성 중 하나는 전체 입력 문장이 하나의 벡터로 압축된다는 것입니다. 이 문장 공간에서 문맥 벡터 공간으로의 맵핑이 존재하며, 인코더 디코더 모델을 훈련시켜 이 맵핑을 찾아..
lv99.tistory.com
attention은 다양한 종류가 있고, 비슷한 성능을 낸다고 알려졌지만 attention is all you need의 저자는 dot-product attention의 장점에 대해 이렇게 설명합니다. "much faster and more space-efficient in practice". 따라서 이 구조의 attention을 기반으로 multi-head attention이 설계되며, 트랜스포머에서는 이것을 3가지 다른 방법으로 사용합니다.

1. "인코더-디코더 어텐션"레이어에서, Q는 이전 디코더 레이어에서오고 메모리 K와 V는 인코더의 출력에서 옵니다. 이를 통해 디코더의 모든 위치가 입력 시퀀스의 모든 위치를 attend할 수 있습니다. 이것은 seq2seq모델에서의 일반적인 인코더-디코더 어텐션 메커니즘입니다.
2. 인코더에는 self-attention 레이어가 포함됩니다. self-attention 레이어에서 모든 K, V는 동일한 위치(인코더에서의 이전 레이어의 출력)에서 가져옵니다. 인코더의 각 위치는 인코더의 이전 레이어에 있는 모든 위치에 attend할 수 있습니다.
3. 디코더 내의 self-attention 레이어들은 디코더 내의 각 위치가 디코더 내의 모든 위치까지 그 위치를 포함하여 attend할 수 있게합니다. auto-regressive 속성을 유지하기 위해서 디코더에서 왼쪽으로 흐르는 정보를 막을 필요가 있습니다. 허용되지 않은 연결에 대응하는 softmax의 입력에서 모든 값을 마스킹 아웃(-∞로 설정)하여 scaled dot-product 어텐션을 구현합니다.
디코더에서의 self-attention은 "Masked" multi-head attention입니다. 왜 encoder와 다르게 "masked"가 추가되는 것일까요? 일반적으로 디코더는 학습할 때에 이전의 출력값에 의존합니다. 그런데, 이전의 값에 오류가 있다면 그 오류에 의존하여 계속 잘못된 디코딩이 진행됩니다. 이러한 것을 막기 위해 이전값은 정답으로부터 가져오도록 하는 것이 Teacher Forcing 기법입니다.
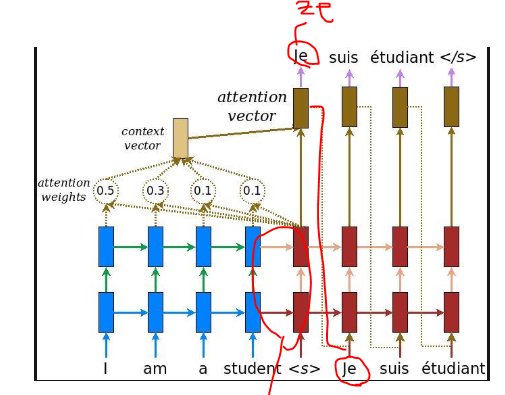
예를들어 I am a student를 Je suis etudiant 라는 문장으로 번역하는 것을 학습한다고 해봅시다. 디코더(빨간색)의 첫번째 스탭을 통해서 계산된 결과는 Je가 됩니다. I에 해당하는 것이죠. 그런데 이것이 Ze로 잘못 예측되었다고 해봅시다. (학습 초기에는 성능이 좋지 않기 때문에 잘못 예측될 경우가 많습니다.) 그러면 Ze가 다음 스탭에 전달될 것이고, 이것은 오류를 전달받는 것이 됩니다. 이전 출력값을 입력으로 받는 모델에서는 치명적이기에 학습이 제대로되지 않습니다. 따라서 이전 스탭에서 Ze로 출력이 되더라도 상관없이 그 다음 스탭에서는 정답인 Je를 이전 출력으로 입력받아 학습을 진행합니다. 1번 문제가 틀리면(사실 맞아도 상관 없이), 1번의 답을 알려주고 2번의 문제를 풀게하는 이 방법이 teacher forcing입니다. (실패가 최고의 선생님이라고 말하는 요다랑 다르게, 정답이 최고의 선생이라는 teaching forcing 기법...)

seq2seq 모델은 RNN 기반이기 때문에 현재 스탭을 학습할 때에는 이후 값을 알 수 없었기에 이전값으로 학습이 진행이 됩니다. 그런데 transformer는 attention을 통하여 앞이든 뒤든 다 볼 수 있게 됩니다. 하지만, 실제 디코딩 상황을 고려하기 위하여 뒤에것은 보면 안됩니다. 보지못하게 하기 위하여 masking을 추가합니다. (inference할 때에는 어짜피 뒤 정보가 없기 때문에 masking할 필요없음)
Self-attention
self-atteiton는 Q=K=V인 경우의 attention을 말합니다. 이 경우에 계산은 4단계로 이루어져있습니다. 먼저 각 인코더의 입력 벡터(각 워드의 임베딩)로부터 세 개의 벡터를 만듭니다. 그런 다음 임베드에 3개의 다른 행렬을 곱하여 각 단어에 대한 Q, K, V 벡터를 만듭니다. 두번째 단계로, 우리가 score를 계산할 각각의 워드의 Q와 K의 점곱(내적)으로 <q_{t}, k_{s}>를 계산합니다. 이 attention score는 특정 위치에서 단어를 인코딩 할 때 입력 문장의 다른 부분에 집중할 정도를 결정합니다. 세번째 단계로, attention/softmax score가 되도록 나눕니다. 흥미롭게도 이 구조를 Z가 지수의 합과 같은 sotmax로 바꿀 수 있습니다. 이 attention score는 위치에서 각 단어가 얼마나 표현될지를 결정합니다. 분명히 이 위치의 단어는 가장 높은 softmax score 갖지만, 때로는 현재 단어와 관련된 다른 단어에 attend하는이 유용합니다. 마지막 단계로, 각 V 벡터에 attention score를 곱한 다음 weighted value vector들을 더합니다. 이것은 이 위치에서 (attention 모델의 context vecotr와 유사한) self-attetion layer의 출력을 생성합니다. self-attention의 결과 벡터는 feed-forward 신경망에 보낼 수 있는 벡터가 됩니다.
Multi-head attention
attention head를 여러개 갖는 것을 multi-head attention이라고 한다. 각각의 attention head는 다른 Q, K, V 가중치 행렬들을 갖고, Q, K, V 행렬들을 결과로 갖는 어텐션을 계산한다. 그리고 그 Z를 모두 모아서(concat) 가중치 행렬과 곱해서 레이어의 최종 출력값을 만듭니다.
multi-head attention을 하게되면 특정한 하나의 위치에만 크게 집중하는 것이 아니라, 그 집중을 분산시킬 수 있기 때문에- 두번째, 세번째 중요한 위치 등을 효과적으로 학습할 수 있는 장점이 된다.
Positional Encoding
트랜스포머에서 또 중요한 개념 중 하나는 positional encoding입니다. rnn 구조가 더이상 없기 때문에, sequence 순서 정보, position 정보를 이해하기 위해서는 새로운 개념이 필요합니다. 이를 위해서 encoder-decoder의 맨 아래 input embedding에 positional encoding을 추가합니다. 주로 sin/cos 함수를 이용해 만들어줍니다.
encoder
0. word embedding
- 자연어를 다루는 모델에서는 모두 갖고 있음. 자연어 자체를 다룰 수 없기에 벡터로 변환
1. positional encoding
- 상대적인 위치 정보를 나타내는 encoding
- 단어의 위치 및 순서 정보를 반영하기 위해 추가된 것
- sin, cos 함수를 이용해 encoding함. (-1~1의 값을 갖고 있고, 길이가 아무리 길어도 상대적인 값을 넣을 수 있기에 장점)
- Residual connection
- positional encoding이 손실될 수 있기 때문에 residual connection으로 다시 한번 더해줌
- layer normalization을 해주어서 학습 효율도 증대
2. self-attention
- encoder에서 이루어지는 attention 연산 = self-attention
Query (Q)
Key (K)
Value (V)
워드 임베딩에 weight(q, k, v)를 곱해서 Query, Key, Value를 계산
- Query * Key = attention score
- 값이 높을 수록 연관성이 높고, 낮을 수록 연관성이 낮다.
- key의 차원수로 나누고 softmax
- softmax 결과 값
- key값에 해당하는 단어가 현재 단어에 어느정도 연관성이 있는지 나타냄
- 문장 속에서 지닌 입력 워드의 값 = softmax 값과 value 값을 곱하여 다 더함
- 단순하게 하나의 워드값이 아니라, 문장에서 연관성이 반영된 값이기 때문에 context가 반영이 됨! 이것이 핵심!
3. Multi Head Attention
- 기계 번역에 큰 도움을 줌
- 한개의 attention으로는 언어의 모호성을 인코딩하기에 부족하기 때문에 multi로!
- 연관된 정보를 다른 관점에서 바라보아 보완
Transformer는 이러한 encoder layer를 6개 쌓음.
decoder
1. masked multi head attention
- 지금까지 출력된 값에만 적용하기 위함 (아직 출력되지 않은 값에 대해서는 적용하지 않기 위함)
- task에 따라 활용이 가능
2. multi head attention
- Q: decoder의 입력값 (decoder의 현재 상태)
- K, V: encoder의 최종 출력값 (encoder 출력 값에서 중요한 정보를 decoder의 다음 단어에 가장 적합한 단어를 출력)
3. Feed forward
- linear, softmax, 가장 높은 확률을 지닌 값이 다음 단어가 됨
- label smoothing
ref: https://arxiv.org/abs/1706.03762
ref: https://namu.wiki/w/JYP%EC%97%94%ED%84%B0%ED%85%8C%EC%9D%B8%EB%A8%BC%ED%8A%B8
'📚 딥딥러닝 > Concepts' 카테고리의 다른 글
| Attention Mechanism (Jointly Learning to Align and Translate) [설명/요약/정리] (0) | 2020.01.09 |
|---|---|
| 메트릭 러닝과 트리플렛 로스 (Metric Learning and Triplet Loss) [설명/요약/정리] (0) | 2020.01.08 |
| ResNet (Shortcut Connection과 Identity Mapping) [설명/요약/정리] (0) | 2019.12.31 |
| 가중치 초기화의 모든 것 (All about weight initialization) [설명/요약/정리] (1) | 2019.12.23 |
| AutoEncoder (self-supervised learning) [설명/요약/정리] (1) | 2019.12.20 |