Attention Mechanism (Jointly Learning to Align and Translate) [설명/요약/정리]
Encoder-decoder 모델에서 중요한 특성 중 하나는 전체 입력 문장이 하나의 벡터로 압축된다는 것입니다. 이 문장 공간에서 문맥 벡터 공간으로의 맵핑이 존재하며, 인코더 디코더 모델을 훈련시켜 이 맵핑을 찾아내야 합니다. 이것은 모델 아키텍처(히든 유닛과 파라미터의 수)에 의해 정의된 hypothesis(가설) 공간이 모든 소스 문장에서 컨텍스트 벡터로의 맵핑을 포함한다는 가정에 따라 결정됩니다.
attention이라는 새로운 모델의 아키텍처 구조를 추가하는 것은 직관/과학적 관찰에 따라 모델을 대상 작업에 대해서 더 나은 작업을 수행하도록 하는 것이 목표입니다. encoder-decoder 모델을 이용한 기계번역 문제에서 attention을 적용하였을 때 최대 60%의 성능이 향상되었다고 합니다.
현재는 어텐션, 어텐션 하지만, 처음 소개될 때에만 하더라도 어텐션이 이렇게 강하게 사용될지 몰랐던 것 같습니다. "NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE"이라는 논문에서 처음 발표가 되었는데요. 저자를 살펴보면, Dzmitry Bahdanau (Jacobs University Bremen, Germany), KyungHyun Cho, Yoshua Bengio∗ (Universite de Montr´eal)입니다. 현재 뉴욕대에서 교수를 맡고계신 조경현 교수님(펄럭)과 포닥시절 몬트리올 대학에서 함께하신 딥러닝 3대장 중 한명인 조슈아 벤지오 교수님. ICLR 2015년에 발표되었는데, 자연어처리를 공부하시는 분이라면 읽어보시길 추천드립니다.
attention이라는 단어는 논문에 3번 등장합니다! :) 주요 문장을 살펴보면,
The decoder decides parts of the source sentence to pay attention to.
By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed length vector.
With this new approach the information can be spread throughout the sequence of annotations, which can be selectively retrieved by the decoder accordingly.
저는 핵심 문장이 이것이라고 생각합니다. "어텐션 메커니즘은 소스 문장의 모든 정보를 고정 길이 벡터로 인코딩해야하는 부담으로부터 완화시킨다." 이것은 기존의 seq2seq 모델의 문제점이던 고정 길이 벡터로 모든 정보를 인코딩하면서 생기는 정보 손실 문제에 대한 부분을 해결합니다.
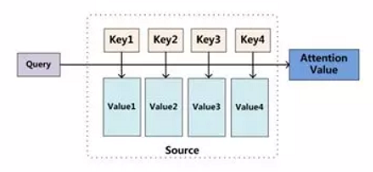
어텐션은 Q(query), K(key), V(value) 3개의 벡터를 입력으로 받아 query와 key-value 쌍을 출력에 맵핑하는 것으로 설명될 수 있습니다. 각 값에 할당된 가중치는 해당 key에 대응되는 query에 대한 유사도로 계산됩니다. 자주 사용되는 유사도 계산 함수에는 dot product, splice, detector 등이 있습니다. 이렇게 얻은 어텐션 가중치는 softmax 함수를 사용하여 각 확률의 합이 1이되도록 정규화합니다. 마지막으로 V에 대응하는 가중치들에 가중을 더하고 최종 attention을 얻습니다. (현재 대부분의 NLP에서는 K=V이고, self-attention 모델에서는 Q=K=V 입니다.)

위 그림에서는 softmax 내에 들어가는 function(Q, K)는 위에서 설명한것을 포함하여 dot, general, concat, perceptron으로 수식으로 표현합니다. 그 계산된 값인 유사도(혹은 energy)가 softmax를 통과하며 정규화된 것을 attention distribution이라고 합니다. 그리고 이것에 가중치인 인코더의 hidden state(V)를 곱해 가중합을 구한게 "최종" attention vector(context vector)가 됩니다.
context 의미?
seq2seq 모델에 적용된 attention은 Q가 decoder의 hidden state / K, V가 encoder의 hidden state로서 사용됩니다. seq2seq모델에서 디코더의 initial hidden state는 인코더의 마지막 hidden state가 됩니다. 이것은 인코더의 전체 step에 대한 정보를 담고 있기 때문에, 이것이 문장의 맥락 정보가 반영되어있는 context vector가 됩니다.

여기서 사용되는 context는 입력 문장이 인코더를 통해 압축된 정보를 담고 있는 것이고, 앞서 attention에서의 context는 K->V 맵핑하는데 있어서 어떤것에 집중할지를 알아내고, 그 집중할 정도를(정보를) 담아낸 것입니다.
그리고?
그런데, 어텐션은 RNN 기반의 seq2seq 모델의 성능을 향상시키는 메커니즘으로 논문에서 소개되었지만, "attention is all you need"라는 논문을 통하여 병렬처리가 어려워 연산 시간이 오래걸리는 RNN을 벗겨내고 새로운 모델인 트랜스포머에 주요한 역할로서 사용됩니다. 또한 기존의 RNN 계열에서는 순차적이라는 것이 장점이었지만, 동시에 한계를 갖습니다. 가까운 단어에 대해서만 의미를 강하게 가질 수 있기 때문입니다. 하지만, attention을 통하여 멀리 있는 단어까지도 연관성(유사도)을 크게 가질 수 있어서 언어를 이해하는 능력을 한층 높입니다.
'📚 딥딥러닝 > Concepts' 카테고리의 다른 글
| AutoML의 대표작: 신경망 아키텍쳐 탐색(Neural Architecture Search; NAS) (0) | 2020.01.31 |
|---|---|
| 딥러닝에서 바닐라 모델(Vanilla Model)과 베이스라인 모델(Baseline Model) [설명/요약/정리] (0) | 2020.01.13 |
| 메트릭 러닝과 트리플렛 로스 (Metric Learning and Triplet Loss) [설명/요약/정리] (0) | 2020.01.08 |
| Transformer: All you need is Attention (설명/요약/정리) (2) | 2019.12.31 |
| ResNet (Shortcut Connection과 Identity Mapping) [설명/요약/정리] (0) | 2019.12.31 |