가중치 초기화의 모든 것 (All about weight initialization) [설명/요약/정리]
딥러닝의 가장 일반적인 문제, 그래디언트 소멸 및 폭발 (Vanishing / Exploding Gradient) 문제를 해결하기 위한 방법 중 하나로 가중치 초기화가 있습니다. 이것은 overfitting/underfitting, local minimum에 수렴 혹은 수렴하지 못하는 문제를 야기하기도 하죠. 따라서 딥러닝에서 가중치를 초기화하는 것은 매우 중요합니다. 각 뉴런(노드)들은 가중치 값을 갖고 있고, 이것을 학습하여 어떠한 '지식'의 형태로서 문제를 해결하는데 사용됩니다. 어떤 값으로 초기화하는지는 이후의 과정과 독립적이지 않고, 시너지가 있는 조합이 있습니다. 어떤 가중치들이 있고, 어떤 활성화 함수와 사용되는지 살펴봅시다.
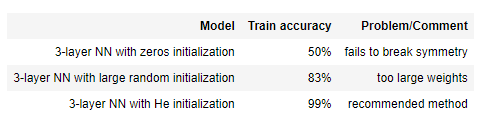
- 초기화를 0으로 한다면?
학습이 안됩니다. 모든 노드들이 같은 값을 갖고 있는 것 만으로도 문제가 되는데, 그 값이 0 이기 때문에 곱셈에 치명적입니다.
- 초기화를 너무 크거나 작은 값으로 한다면?
학습이 잘 되지 않음. 예를들어 초기화를 매우 작은 값으로 한다면, 그래디언트도 매우 작아서 학습이 잘되지 않는다.
그러면 어떻게 해야할까요? 과거의 방법들 말고 자주 사용하는 두가지를 알아봅시다! 그것은 논문의 저자 이름을 따왔는데요, Xavier Glorot의 이름을 따서 Xavier (혹은 Golorot) initizalization과 Kaiming He의 He Initialization 방법이 있습니다.
Xavier Initialization은 레이어의 출력 분산을 입력의 분산과 동일하게 만드는 초기화 기술입니다. 이 아이디어는 실제로 매우 유용한 것으로 판명되었고, 많이 활용되고 있습니다! ReLU가 제안되고 나서는, He initilization이 제안되었으며 이것이 요즘의 방법들에는 많이 사용되고 있습니다. (두 초기화 방법 모두 논문의 핵심주제가 되는 것은 아닙니다.)
결론,
가중치 초기화의 장점
- 그레디언트 하강의 수렴 속도
- 낮은 학습 및 일반화 오류로 수렴하는 그레디언트 하강의 확률 증가 (먼소리지.. 어디서 온겨...)
ReLU Family -> He initialization
Sigmoid, Tanh -> Xavier initialization
Xavier initialization uses a scaling factor for the weights W[l] of sqrt(1./layers_dims[l-1]) where He initialization would use sqrt(2./layers_dims[l-1]).)
오랜만에 복습을 해보았는데, 케라스의 initializer들도 잠깐 살펴보죠.
Zeros, Ones, Constant
RandomNormal, RandomUniform, TruncatedNormal, VarianceScaling, Orthogonal, Identity
lecun_uniform, lecun_normal, glorot_uniform, glorot_normal, he_uniform, he_normal
생각보다 많이 구현되어있었습니다. keras에서는 default initializer로 glorot_uniform을 채택하고 있습니다. he와 glorot을 선형/비선형에 맞추어 활용하는 것이 좋습니다. 사실 이보다는 custom initializer를 만드는 것이 궁금했는데 간단히 설명이 되어있습니다.
from keras import backend as K
def my_init(shape, dtype=None):
return K.random_normal(shape, dtype=dtype)
model.add(Dense(64, kernel_initializer=my_init)shape (초기화할 변수의 모양)과 dtype(생선된 값의 dtype)을 argument로 주면 된다고 합니다! :)
ref: http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
ref: https://arxiv.org/pdf/1502.01852v1.pdf
ref: Katanforoosh & Kunin, "Initializing neural networks", deeplearning.ai, 2019.
ref: Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
ref: https://stackoverflow.com/questions/46883606/what-is-the-default-kernel-initializer-in-keras