[TF 2.0] BERT revision in Tensorflow 2.0 (BERT for TF 2.0)
목차
1. BERT 간단 설명
2. Tokenizing with Word Piece Model(WPM) (pre-processing)
2. Embedding layer in BERT
3. BERT Architecture (버트 구조)
4. BERT Training (버트 학습방법)
5. BERT를 keras에서 사용해보기
BERT 간단 설명
BERT(Bidirectional Encoder Representations from Transformers)는 트랜스포머 기반의 Language (Representation) Model(이하 LM)입니다. google이 공개를 했으며, 등장하자마자 엄청난 성능으로 모두에게 충격을 안겨주었죠. 드디어 NLP의 영역에서도 강력한 모델이 등장합니다. 다른 Language Model과 마찬가지로, 대량의 text로부터 학습을 해야 성능이 나오기 때문에 Unsupervised Learning 방식을 택하였고, general-purpose의 language understanding 모델을 학습하려는 목적을 갖고 만들어졌습니다. 그래서 BERT는 general하기 때문에, 여러 작은 task들로 fine-tuning해서 푸는데 적합했습니다. BERT라는 큰 모델을 갖고 작은 task들을 풀기에 이러한 fine-tuning을 downstream이라고 부르며, 해당하는 task들을 downstream task라고 부릅니다. 대표적인 LM의 성능평가 방식은 GLUE로, 11개의 task들로 이루어져있습니다. BERT가 등장하고, 이 11개의 task에 대해서 SOTA의 성능을 보여 그 명성을 알리었습니다.

Tokenizing with Word Piece Model(WPM) (pre-processing)
Tokenizing은 입력 문장을 token으로 쪼개어 입력시킬 수 있도록 준비하는 전처리과정입니다. 띄어쓰기로 나누는 것이 가장 간단하고, 한글과 영어에서 tokenizing은 다른 방식으로 진행되는 기법들도 있습니다. 한글은 한 글자에 여러 단어가 결합되어있고, 종결어미가 매우 다양하기 때문에 처리하기가 까다롭습니다. BERT에서는 WPM 토크나이징 기법을 채택하였습니다.
WPM은 빈도수를 활용하여 subword 단위로 쪼개는 방식입니다. subword로 쪼개는 이유는 OOV(out of vocabulary) 문제를 해결하기 위함입니다. vocab이라고도 불리우는 vocabulary는 사전입니다. 입력된 단어를 어떠한 값으로 매칭시킬 수 있게 만듭니다. 이 사전이 커질수록 연산해야하는 복잡도가 매우 증가하기 때문에, 갯수의 한계가 어느정도 존재합니다. 하지만, 무한하게 계속해서 사전에 없는 단어들이 생겨나고, 자주 쓰지이지 않는 단어들에 대해서는 어떠한 처리도 할 수 없습니다. 여기서의 사전은 빈도수로 많이 나오는 것부터 시작하여 일정한 갯수로 자르는게 일반적입니다. 즉, 사전 내의 단어들에 대해서만 대응을 할 수 있고, 사전 밖에 있는 단어들에 대해서는 대응을 할 수 없습니다. 이러한 문제를 해결하기 위한 대표적인 방법은 Byte Pair Encoding(BPE)와 Word Piece Model(WPM)이 있습니다. WPM은 글자를 캐릭터 단위로 쪼개고, 우도(likelihood)를 통해서 단어를 분리합니다. WPM으로는 google에서 공개한 sentencepiece을 사용하시면 됩니다.
https://github.com/google/sentencepiece
google/sentencepiece
Unsupervised text tokenizer for Neural Network-based text generation. - google/sentencepiece
github.com
Embedding layer in BERT
입력에 가장 가까운 Embedding 부터 살펴봅시다. NLP에서 Embedding 레이어의 역할 중 가장 중요한 것은 자연어를 인공신경망이 이해(학습)할 수 있는 차원으로 변환하는 것입니다. 앞선 tokenizer를 통해서 입력 문장을 토큰단위로 쪼개고, 해당 토큰을 vocab에 매칭하여 id(숫자)로 입력합니다. 그런데, 이 id는 매우 큽니다. vocab의 사이즈는 보통 5만정도를 사용합니다. 이것을 직접 입력하여 BERT 모델을 구축하면 학습해야하는 파라미터의 수가 엄청나게 많을 것입니다.(지금도 엄청 많은데...ㄷㄷ) 이 차원을 낮추기 위해서 embedding layer를 사용합니다. 결과적으로 단어를 임베딩으로 표현함으로써 단어의 의미적 중요성을 숫자의 형태로 모델링하여 인공신경망이 연산을 효과적으로 수행할 수 있게합니다. 벡터로서 표현하기 때문에 상대적으로 적은 차원의 수로 표현할 수 있게 됩니다.
그리고 Transformer는 위치 관계 정보를 얻기 어려운 어텐션 기반 구조이기 때문에, Positional Encoding을 추가하였습니다. BERT에서는 이 positional encoding을 embedding으로 사용하고, 문장을 구분하는데(downstream task의 성격에 맞게 활용됨) 사용되는 segment embedding이라는 것을 추가하여 총 3개의 embedding을 통합하여 embedding합니다.
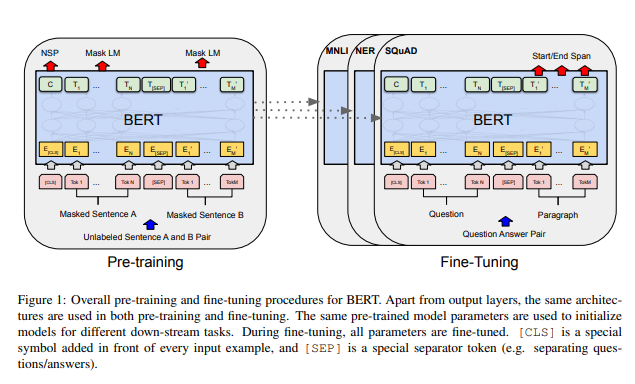
BERT Architecture (버트 구조)
BERT Base model
- Sequence=512
- L=12
- H=768
- A=12
- Total parameters = 110M
BERT Large model
- Sequence=512
- L=24
- H=1024
- A=16
- Total parameters = 340M
L: 레이어(Transformer Block)의 수
H: hidden size
A: Self-attention heads의 수
BERT Training (버트 학습방법)
BERT의 학습은 두 task로 이루어집니다.
Task #1: Masked LM
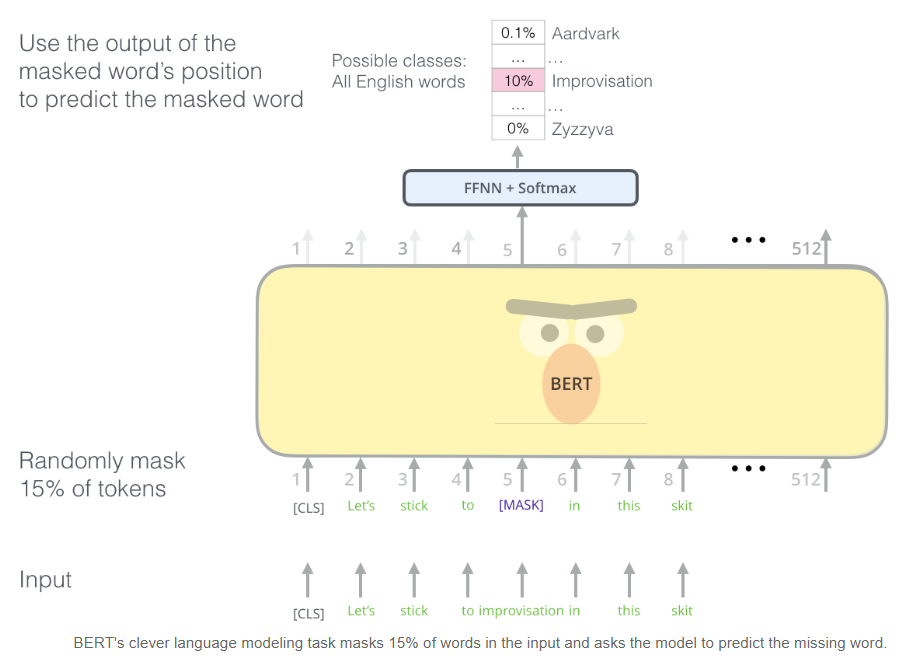
BERT는 인코더의 transformer stack을 학습시키는 방법으로 "masked language model"개념을 도입했습니다. 즉, 입력값에서 특정 토큰들을 masking(감추는 것)하고, 그 위치에 있어야 하는 토큰을 예측해내는 문제입니다. 입력의 15%를 masking하는 것 외에도 BERT는 나중에 모델을 fine-tuning하는 것을 향상시키기 위해 때로는 단어를 임의로 다른 단어로 바꾸고, 해당 위치에서 올바른 단어를 예측하도록 모델에게 요청합니다.
Task #2 Next Sentence Prediction (NSP)
BERT가 여러 문장 사이의 관계를 잘 처리할 수있도록 다음 문장이 무엇인지 예측하는 task에 대해서 학습합니다. 두 문장 A와 B가 주어지면, A 문장 다음에 오는 문장은 B인지 아닌지 판단하는 문제입니다. (최근에 BERT보다 발전된 모델에서는 이 task 보다는 문장의 일관성을 예측하는 SOP(Sentence-Order Prediction) task가 학습하기에 좋다고 평가받고있습니다.)
BERT를 tensorflow 2.0에서 사용해보기
https://github.com/kpe/bert-for-tf2
kpe/bert-for-tf2
A Keras TensorFlow 2.0 implementation of BERT, ALBERT and adapter-BERT. - kpe/bert-for-tf2
github.com
공개된 github를 사용해보고자합니다. 현재도 업데이트가 진행되고 있어서, documentation이랑 함수 이름이나 경로가 조금씩 바뀌기도 합니다. 참고하셔서 사용하시면 좋을 것 같습니다! :)
pip install bert-for-tf2
(github 최신 버전과 다를 수 있습니다)
import bert
model_dir = ".models/uncased_L-12_H-768_A-12"
bert_params = bert.params_from_pretrained_ckpt(model_dir)
l_bert = bert.BertModelLayer.from_params(bert_params, name="bert")BERT 모델을 읽어올 때, 귀찮은 config 설정들이나 모델 구현을 미리 다 해두어서 사용만 하면 위처럼 손 쉽게 모델이 로드됩니다 :)
from tensorflow import keras
max_seq_len = 128
l_input_ids = keras.layers.Input(shape=(max_seq_len,), dtype='int32')
l_token_type_ids = keras.layers.Input(shape=(max_seq_len,), dtype='int32')
# using the default token_type/segment id 0
output = l_bert(l_input_ids) # output: [batch_size, max_seq_len, hidden_size]
model = keras.Model(inputs=l_input_ids, outputs=output)
model.build(input_shape=(None, max_seq_len))
# provide a custom token_type/segment id as a layer input
output = l_bert([l_input_ids, l_token_type_ids]) # [batch_size, max_seq_len, hidden_size]
model = keras.Model(inputs=[l_input_ids, l_token_type_ids], outputs=output)
model.build(input_shape=[(None, max_seq_len), (None, max_seq_len)])모델을 가져다가 keras에서 사용하려면 위와 같이 하면 됩니다! :)
ref: https://arxiv.org/pdf/1810.04805.pdf
ref: https://towardsdatascience.com/fine-tuning-bert-with-keras-and-tf-module-ed24ea91cff2
ref: https://github.com/gaphex/bert_experimental
ref: https://colab.research.google.com/drive/1ofSfThTBlWjOx5dqXmdsIol-MdiqCyZC
ref: https://www.analyticsvidhya.com/blog/2019/09/demystifying-bert-groundbreaking-nlp-framework/