TabNet 리뷰! 드디어 table (정형 데이터)를 위한 효과적인 딥러닝(인공신경망) 모델이 나타났습니다! xgboost, lgbm, catboost과 같은 decision tree-based gradient boosting 기법들의 장점을 이용한 모델
TabNet 리뷰! 드디어 table (정형 데이터)를 위한 효과적인 딥러닝(인공신경망) 모델이 나타났습니다!
xgboost, lgbm, catboost과 같은 decision tree-based gradient boosting 기법들의 장점을 이용한 모델입니다!
제가 생각하는 key contribution은 다음 2가지 입니다.
1. 정형 데이터에 대해서는 기존의 decision tree-based gradient boosting(xgboost, lgbm, catboost)와 같은 모델에 비해 신경망 모델은 성능이 떨어진다. 두 구조의 장점을 모두 갖는 TabNet을 제안
2. feature selection, interpretability가 가능한 신경망 모델
0. 서론
제가 현재 참가하고 있는 신약개발 대회 MoA에서 TabNet이 가장 높은 성능을 보이고 있습니다.
이전의 정형 데이터에서는 lgbm이 항상 가장 좋았고, 앙상블을 고려할 때 xgboost, catboost, 그리고 NN(neural network)를 추가하는 정도였습니다. 사실 정형 데이터에 대해서는 NN은 그렇게 복잡하거나 깊은 레이어로 구성되지도 않고, 그 구조에 이것저것 많이 넣는다고 해서 특별히 좋아지지는 않았습니다. 그나마 쓸만했던 것은 autoencoder를 이용해서 노이즈를 제거하거나, PCA와 같이 차원 축소로 사용하거나, 적은 데이터로 학습을 하는 semi-supervised 혹은 self-supervised 방식에 활용되는 정도였습니다. 여기에 조금 양념을 쳐서 anormaly detection(이상치 검출)로 엮어가기도 하죠. 쓰고보니 쓸모가 많은 것 같기도 하네요...ㅋㅋ
그런데, 이제 이러한 decision tree-based gradient boosting의 장점을 가진 인공신경망 아키텍쳐를 제안한 논문이 발표되었습니다! 심지어 feature engineering과 selection도 처리해준다고 합니다. 인공신경망 모델에서 또 중요한 이슈 중에 하나는 설명가능(interpretability)하게 만드는 것입니다. 이것도 가능하다고 합니다! Google Cloud AI의 Serean님과 Tomas님이 연구한 결과입니다! 정형데이터 tabular data를 갖고 연구하시는 분들은 꼭 한번 사용해보시면 좋을 것 같습니다!
Abstract

이 논문에서는 새로운 고성능 및 해석 가능한 표준 심층 테이블 형식 데이터 학습 아키텍처 인 TabNet을 제안합니다. TabNet은 순차적인 어텐션(Sequential Attention)을 사용하여 각 의사 결정 단계에서 추론할 feature를 선택하여 학습 능력이 가장 두드러진 기능에 사용되므로 interpretability와 효과적인 학습을 가능하게 합니다. 실험적으로 다른 신경망 및 변형된 decision tree보다 성능이 우수하다는 것을 증명합니다. 끝에는 self-supervised learning으로 레이블이 없는 데이터가 풍부할 때, representation learning의 성능을 효과적으로 향상시키는 것을 보여줍니다.
1. Introduction

이렇게 좌에서 우로 sequential하게 (masking을 이용하여) feature를 seleciton해가면서 feedback을 주고, 학습해나아가는 구조입니다.

현재 깃헙에서 조금 아쉬운 부분은 unsupervised pre-training 코드가 아직 제공되지 않는다는 점입니다. github issue에서는 이 부분이 얘기되고 있고, 다른 contributor 2명이 제안한 두 PR이 있는 것은 확인하고 있는 상황입니다. 제가 학습해본 것은 supervised 부분이고, 대부분 이 approach로 성능을 내고 있습니다. (하지만 unsupervsied training까지 하면 성능이 더 좋을 것으로 생각됩니다.)
tabnet encoder를 통해서 feature engineering 효과를 내고, decision making 부분을 통해 feature selection이 이루어지는 것으로 저는 이해했습니다! encoder는 fine-tuning하면서 task에 맞게 성능을 향상시켜 맞춰갑니다.
3. TabNet for Tabular Learning
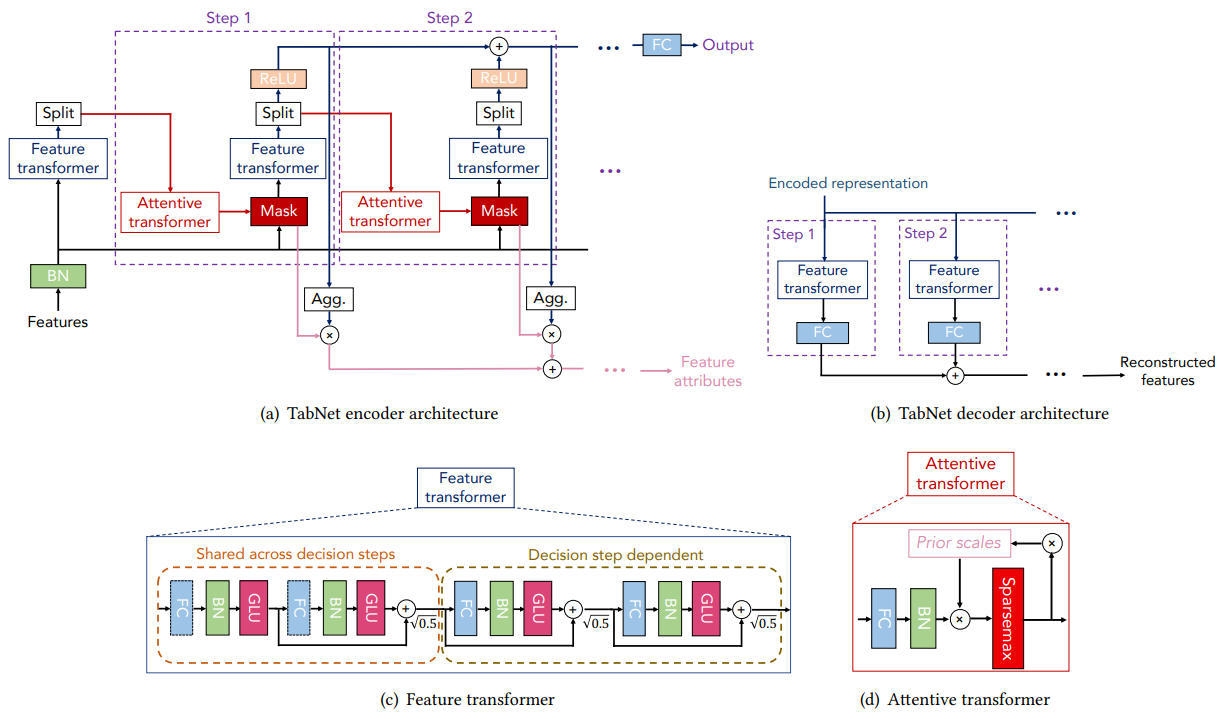
(a) TabNet의 encoder는 각 decision step에 대해서 feature transformer, attentive transformer, feature masking으로 구성됩니다.
(b) TabNet의 decoder는 각 단계에서 feature transformer 블록으로 구성됩니다.
(c) Feature transformer(4-layer 네트워크 구조)의 블록 중 2 레이어는 모든 decision 단계에서 공유되고, 나머지 2 레이어는 decision 단계에 의존합니다. 각 레이어는 Fully-Connected Layer(FC)와 Batch Normalization(BN), GLU(Gated Linear Unit) 로 구성됩니다.
(d) Attnetive transformer 블록. prior scale information는 현재 decision step 이전에 각 feature가 얼마나 많이 사용되었는지를 집계한 정보입니다. 이것을 단일 레이어에 맵핑하여 사용합니다. 계수의 정규화는 각 decision step에서 가장 두드러진 특징을 sparse하게 선택하기 위해 sparsemax를 사용하여 학습이 수행됩니다.
4. Tabular Self-supervised Learning
사실 논문에서도 이 부분은 한단락밖에 서술이 되어있지 않습니다.
인코더에 의해 인코딩된 표현(representation/embedding)에서 tabular feature를 재구성하는 decoder를 제안합니다. decoder는 각 decision step에서 (feature transformer 블록 + FC 레이어)으로 구성됩니다. 결국 table의 특정한 영역을 masking하고 인코딩된 표현으로부터 잘 예측해낼 수 있도록 학습하는 것입니다.
5. Experiments
실험 성능은 다양한 데이터셋에 대해서 증명되었습니다.
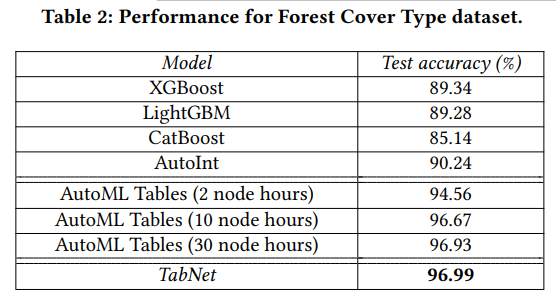


이것보다 실험 결과가 더 많은데, 자세한 것은 논문을 참조해주세요! 결국 TabNet이 좋다는 결과라는 것은 동일합니다.
+ Kaggle
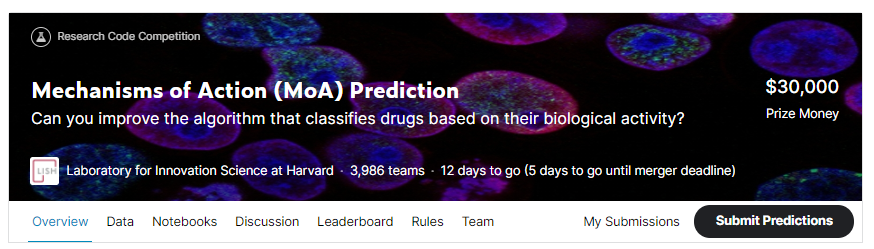
현재 케글에서 이 대회는 Havard의 연구소의 주최로 열리고 있습니다. Connectivity Map 프로젝트에 관한 연구로 5000개 이상의 약품에 대한 MoA 어노테이션 데이터를 제공해줍니다. 약 900개 정도의 feature(column)이 주어집니다. 이것을 갖고 약 200 종류의 Action을 예측하는 multi-label classification 문제입니다. 어떠한 한 action이 단독적으로 일어나는 것이 아니라, 동시에 여러 action이 일어날 수 있다는 것입니다. 이 대회의 총 상금은 3만 달러입니다.
실제로 테스트를 해보았을 때에는, MoA에서는 상당히 좋은 성능을 보였지만, Riiid! (뤼이드)의 케글 컴피티션에서는 별로 좋지 않은 성능을 보였습니다. 조정해야할 파라미터가 아직 많이 남아있긴 하지만, 절대적으로 좋다고 하기는 어려울 것 같습니다. 사실 신경망모델 치고는 조절해야할 파라미터가 조금 많다는 것은 조금 문제입니다. parameter search하는데 시간이 많이 들 것 같습니다.
정형 데이터에 대한 모델 연구나 방법론이 한정적이라고 생각했는데, 이렇게 끝없이 발전하고 있다는 것에 놀랐습니다. 통계적으로 이런 저런 그래프 그려보며, 주어진 정보에 대해 fit하게 feature engineering을 하는 것으로 생각했는데, 아직 모델, 방법론적 측면에서도 발전할 여지가 보입니다! (전자의 경우에는 주어진 data에 너무 overfit 되는 경향이 없지않아 있다고 생각합니다.) 아무련! 저도 이러한 연구를 하고 싶네요~! 다들 화이팅입니다!
p.s. 한국의 기업이 케글에 대회를 여는 것이 너무 반갑고, 감사합니다. 여러분들도 관심갖고 참여해보시면 좋을 것 같습니다! 국내의 공모전을 폄하하려는 것은 아니지만, kaggle은 정말 전세계의 최상위권 분들이 보여 경쟁을 펼치며, 자신의 소스코드와 경험을 공유하는 장입니다. 경력이 오래되신 분들도 많고, 우리가 꿈꾸는 기업에 다니시는 분들도 많습니다. 꼭 대회에서 상금을 타겠다는 목적이 아니라, 그들의 발자취를 따라 실전 데이터로 (문제화 되어서 실전보다 더 어렵기도 한) ML/DL 문제를 해결하는 노하우를, EDA를 경험해나갑시다! 요즘 사교육기관이 넘쳐나기는 하지만, 함께 성장하는 커뮤니티도 많다고 생각합니다. 특히, 제가 운영하는 가짜연구소를 추천드립니다!! :) 오픈의 가치를 실현하기 위해 노력하고 있으며, 강의자료나 교육자가 갖춰진 것보다 더 신선하고, 빠른, 힙한! 주제와 모델을 다루고 있습니다. 커뮤니티이기 때문에 가능한 것이 아닐까요? 기초부터 트랜디한 것까지 다양한 그룹이 무료로 동시에 열리고 있으니 많이 관심가져 주세요!! :)