Semi-Supervised Learning(준지도학습)과 Pseudo-labeling(수도레이블링) 개념정리
1. 레이블과 학습
지도학습(Supervised Learning)은 정답 레이블 데이터가 있는 학습을 말하고,
비지도학습(Unsupervised Learning)은 정답 레이블이 없는 데이터를 이용한 학습을 말합니다.
준지도학습(Semi-Supervised Learning)은 정답 레이블이 있는 작은 데이터셋으로 1차 (지도)학습을 하고, 정답 레이블이 없는 큰 데이터셋으로 2차 학습을 하는 것을 말합니다. 여기서 2차 학습에서 사용되는 대표적인 기법이 수도 레이블링(pseudo-labeling)입니다.
데이터에 정답 레이블을 만드는 과정을 태깅(tagging/annotation/labeling)이라고 합니다. 이러한 과정에는 상당한 노력과 비용이 듭니다. 심지어 성능에도 많은 영향을 미칩니다. 잘못 태깅된 데이터가 많을 수록 성능은 좋지 못합니다. 또한, 학습데이터의 태깅을 어떠한 형식으로 하느냐에 따라서, 모델이 학습할 수 있는 것이 한정됩니다.
예를들어, 아래의 이미지로 예를 들어봅시다.

단순히 'person'이라는 태깅으로 한다면, 이 데이터는 단순 분류의 문제를 푸는데 사용될 수 있습니다.
그런데 이 데이터를 'sweatshirts', 'orange' 'cute' 등 여러개로 태깅을 한다면, 여러 레이블을 동시에 얻을 수 있는 분류 문제를 풀 수 있습니다. 조금 정리해보면,
Binary Classification : 두 클래스(혹은 참/거짓) 중에 하나로 분류하는 문제
Multi-Class Classification : 여러 클래스 중에 하나로 분류하는 문제
Multi-Label Classificiation : 여러 클래스에 대해서 각각 logit을 둬서 여러 레이블을 찾는 문제
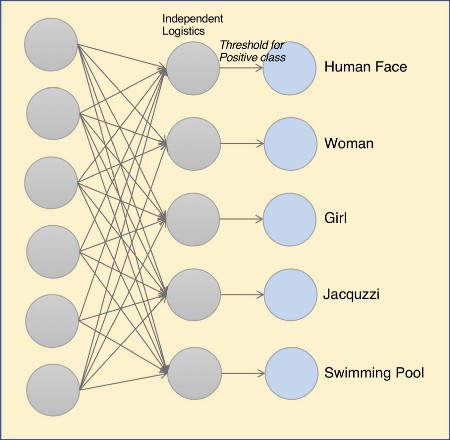
이처럼, 처음에 데이터셋을 구축할 때에는 많은 고민이 필요합니다. 모델의 성능을 한정할 수 있기 때문이죠. 하지만 그렇다고해서 무조건 많은 정보를 담으려고 한다면 그 비용은 극대화될 것입니다.
비용을 최소화하는 방법으로, 태깅을 일부분의 데이터에 대해 수행하고 이를 이용해 러프하게 대략적으로 태깅하는 것을 수도 레이블링이라고 합니다.
2. 수도 레이블링
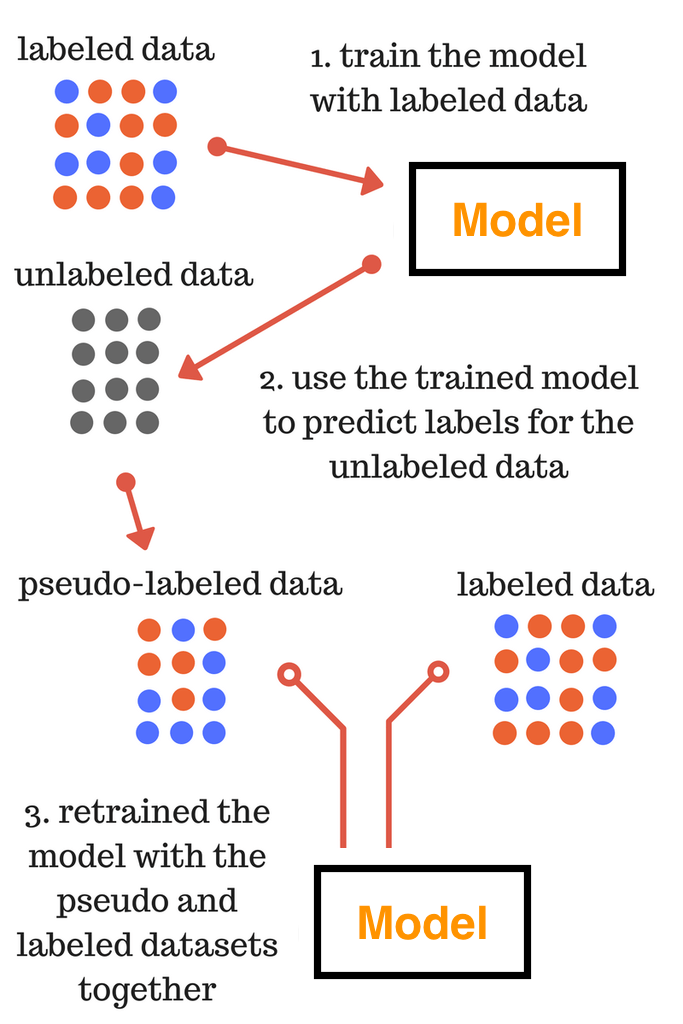
수도 레이블링은 지도학습을 통해 1차적으로 학습된 모델을 이용하여, 태깅이 되지 않은 데이터에 대해 예측을 수행합니다. 수행된 예측 결과를 이용해 가짜(pseudo)로 태깅(labeling)한다고 하여 pseudo-labeling이라고 합니다.
따라서 수도 레이블링을 수행하기 위해서는 학습된 모델이 있어야하고, 태깅되지 않은 데이터가 있어야 합니다.
태깅되지 않은 데이터에 대해서 수도 레이블링을 한 후에는, 이 확장된 큰 데이터셋을 이용하여 2차 학습을 수행합니다.
'📚 딥딥러닝 > Concepts' 카테고리의 다른 글
| Reformer - 트랜스포머(Transformer)를 발전시킨 Re(trans)former (0) | 2020.02.11 |
|---|---|
| 모바일넷(MobileNet), 나스넷(NASNet), 아메바넷(AmoebaNet) - (0) | 2020.02.07 |
| AutoKeras (오토케라스) - 케라스 신경망 구조 탐색(Neural Architecture Search) 프레임워크 (0) | 2020.01.31 |
| AutoML의 대표작: 신경망 아키텍쳐 탐색(Neural Architecture Search; NAS) (0) | 2020.01.31 |
| 딥러닝에서 바닐라 모델(Vanilla Model)과 베이스라인 모델(Baseline Model) [설명/요약/정리] (0) | 2020.01.13 |