Keras baseline using MFCC for Sound Classification
Mel-Frequency Ceptral Coeffienents(MFCC) feature extraction for Sound Classification
https://www.kaggle.com/seriousran/mfcc-feature-extraction-for-sound-classification
MFCC Feature extraction for Sound Classification
Explore and run machine learning code with Kaggle Notebooks | Using data from Cornell Birdcall Identification
www.kaggle.com
Using the MFCC feature for sound classification like the Cornell Birdcall Identification is common. It takes few hours for Cornell Birdcall Identification datasets. I will share extracted feature as dataset after the execution in colab.
In this notebook, I just use 3 mp3 files for each bird class. (check the LIMIT variable)
Please enjoy it and don't forget to vote it.
Feel free to give an advice.
Mel-Frequency Cepstral Coefficients (MFCCs)

The log-spectrum already takes into account perceptual sensitivity on the magnitude axis, by expressing magnitudes on the logarithmic-axis. The other dimension is then the frequency axis.
There exists a multitude of different criteria with which to quantify accuracy on the frequency scale and there are, correspondingly, a multitude of perceptually motivated frequency scales including the equivalent rectangular bandwidth (ERB) scale, the Bark scale, and the mel-scale. Probably through an abritrary choice mainly due to tradition, in this context we will focus on the mel-scale. This scale describes the perceptual distance between pitches of different frequencies.
Though the argumentation for the MFCCs is not without problems, it has become the most used feature in speech and audio recognition applications. It is used because it works and because it has relatively low complexity and it is straightforward to implement. Simply stated,
if you're unsure which inputs to give to a speech and audio recognition engine, try first the MFCCs.
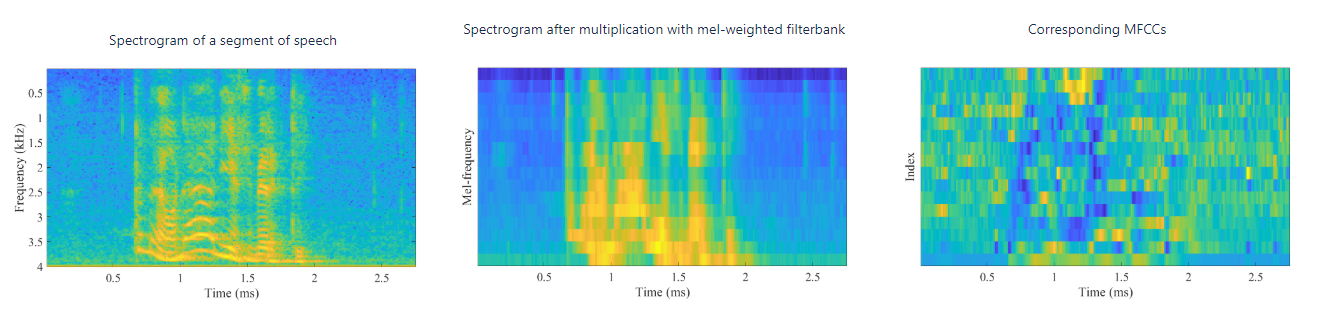
The beneficial properties of the MFCCs include:
Quantifies the gross-shape of the spectrum (the spectral envelope), which is important in, for example, identification of vowels. At the same time, it removes fine spectral structure (micro-level structure), which is often less important. It thus focuses on that part of the signal which is typically most informative.
Straightforward and computationally reasonably efficient calculation.
Their performance is well-tested and -understood.
Some of the issues with the MFCC include:
The choice of perceptual scale is not well-motivated. Scales such as the ERB or gamma-tone filterbanks might be better suited. However, these alternative filterbanks have not demonstrated consistent benefit, whereby the mel-scale has persisted.
MFCCs are not robust to noise. That is, the performance of MFCCs in presence of additive noise, in comparison to other features, has not always been good.
The choice of triangular weighting filters wk,h is arbitrary and not based on well-grounded motivations. Alternatives have been presented, but they have not gained popularity, probably due to minor effect on outcome.
The MFCCs work well in analysis but for synthesis, they are problematic. Namely, it is difficult to find an inverse transform (from MFCCs to power spectra) which is simultaneously unbiased (=accurate) and congruent with its physical representation (=power spectrum must be positive).
ref: https://wiki.aalto.fi/display/ITSP/Cepstrum+and+MFCC
ref: https://melon1024.github.io/ssc/
'📚 딥딥러닝' 카테고리의 다른 글
| YOLOv5 학습 예제 코드 (튜토리얼) - 마스크 쓰고 있는/안 쓴 얼굴(사람) 찾기 (3) | 2020.06.29 |
|---|---|
| YOLO v5 공개! 개념, 이론, 논문 대신에 iOS...? (0) | 2020.06.22 |
| nvidia driver, CUDA 업그레이드 문제 해결 (0) | 2020.06.09 |
| Detectron2 trained model load (architecture and weights) from config and checkpoints (0) | 2020.05.12 |
| nvidia-smi 대신에 nvtop을 쓰자! GPU의 htop 느낌! (1) | 2020.04.04 |